À une époque j’utilisais des feuilles de papier pour gérer les trucs que je voulais faire et avoir la satisfaction de dessiner une coche ou de barrer un truc quand c’était fait. Mais ça s’est vite compliqué quand j’ai vu que c’était très difficile de gérer plein de choses à la fois de cette façon et que des trucs disparaissent au fur et à mesure qu’on tourne les pages. Sans parler des problème de pérennité des cahiers, du manque de recherche ou de filtrage, et pour ce qui est de trier les tâches n’en parlons même pas.
Depuis quelques années, et après avoir essayé moult trucs plus ou moins pratiques et exportables pour les analyser, mes tâches sont rangées dans un fichier tasks.org, qui est un simple fichier texte, dans mon dossier de textes syncronisés. C’est le point de départ de mon wiki personnel plein de notes reliées entre elles.
Pour faciliter l’organisation de tâches je les range d’une façon proche de la méthode para: projet, aires, ressources, frigo.
Voici les entêtes de mon fichier principal:
* Boulot [/]
* Projets [/]
* Aires de responsabilité [/]
** Activités quantifiées globales
** Associations
** Corvées
** Feuille de pognon
** Lieux à visiter
** Rédaction de textes, Communication
** Santé et médical
** Social
** Travaux et bricolage
** Vacances
** Personnes
* Administratif [/]
* Frigo [/]
* Inbox [/]
Les crochets avec un slash dedans servent à compter les sous tâches et sont mis à jour à chaque sauvegarde de fichier.
Les choses pouvant être souvent placées dans plusieurs catégories à la fois, une bonne astuce est de faire usage de tags ou de paraphrases.
Je capture des idées et des trucs à faire soit sur mobile, soit sur ordi, avec une syncronisation entre mes différents postes de travail, ce qui évite d’avoir à reporter des choses en double dans mon système de gestion de tâches constiuté de simples fichiers textes et d’une mise en forme faite par emacs.
Je pratique de temps à autre ce qui s’approche de revue quotidienne, mais non quotidienne.
J’ai essayé de faire des tâches récurrentes pour conserver de bonnes habitudes mais au final cela pollue d’avantage mon agenda qu’autre chose, donc j’ai plutôt marqué ces choses à faire dans les revues peu fréquentes.
J’essaie de faire des revues hebdomadaires, mais sans régularité. Je n’ai pas besoin de passer beaucoup de temps dans mes listes de projets pour les faire avancer spontanément et marquer que plein de tâches ont été faites ou reconsidérées bonnes à jeter entre deux revues.
Pour avoir une synchronisation avec mon agenda NextCloud, j’ai un script cronjob qui prend mon calendrier partagé avec ma femme et le convertit en fichier org, ce qui me permet de voir des évènements en plus dans l’agenda affiché dans emacs.
Je fais aussi en sorte de ne pas utiliser ma boite mail comme un gestionnaire de projet et pratique la méthode Kondo dans mes emails: certains sont à archiver car il se peut vraiment que j’en aie besoin à un autre moment, mais tout le reste n’est que du bruit et a sa place dans un endroit qui ne mérite aucunement mon attention, ils ne sparkent pas la joy, donc hop, poubelle.
J’ai généralement sur mon ordi une instance d’emacs avec mon agenda de la semaine ouvert pour voir à quoi consacrer ma journée.
Les vues filtrées d’agenda sont très utiles pour regrouper des tâches ensemble sur une recherche de mot ou de tag.
Wiki personnel
Toujours dans un maillage de fichiers org, j’utilise org roam pour relier mes écrits par liens directionnels. Le package org-roam-ui permet de voir un graphe interactif de ces liens et de stimuler de nouvelles notes, ou de voir des liens, retrouver des écrits, en créer de nouveaux.
Pour ce wiki, j’ai une page d’index qui relie différents textes que j’ai exporté de mes blogs, certaines thématiques liées à un paquet d’articles et je tente de temps à autre de relier à des billets entre eux et de dégager des thématiques. Ce genre d’outil visuel est un très bon moyen de mettre en perspective ce que l’on souhaite raconter.
Fonctionnalité marrante, org-random-note qui permet d’afficher une note au hasard.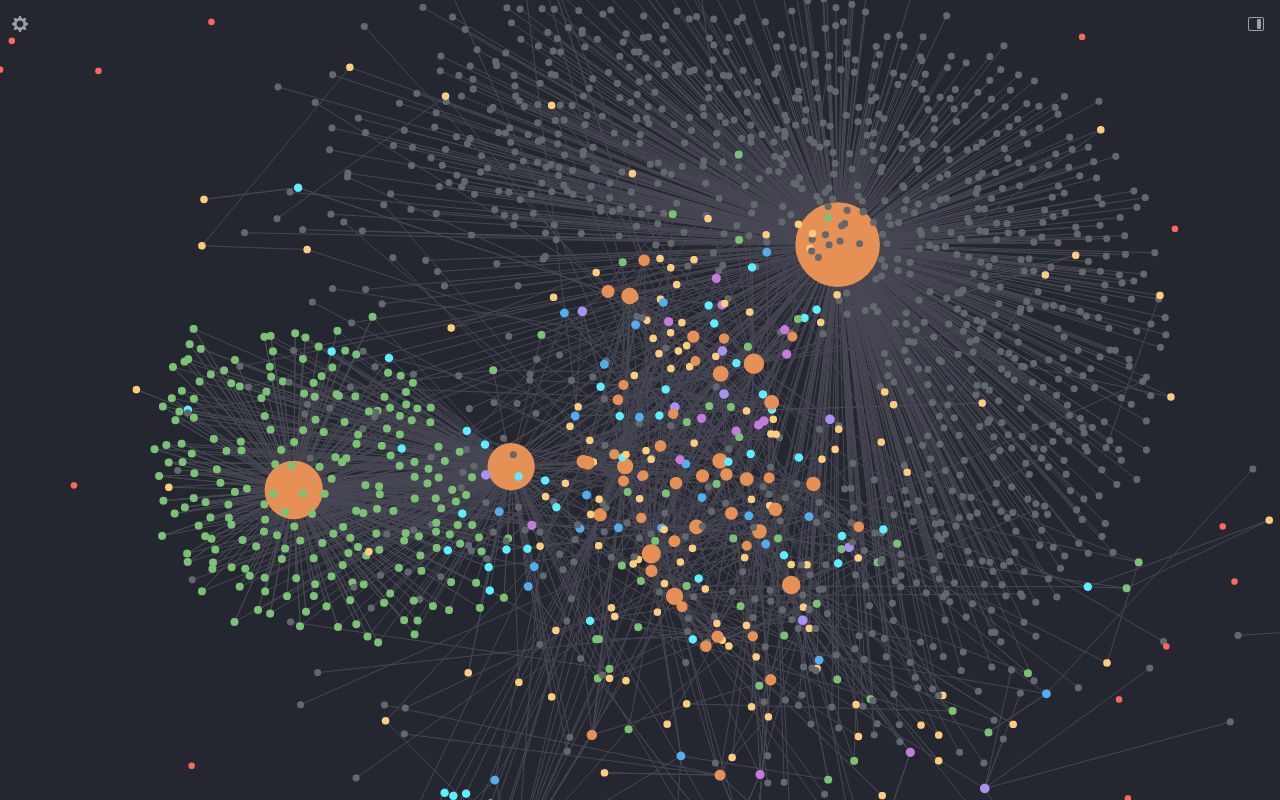
Concilier différents gestionnaires de projet
Certains outils existent pour relier ses tâches orgmode à un service en ligne, mais je ne les ai pas testé.
Les choses liées au boulot ont généralement un gestionnaire de projet en ligne séparé de mon gestionnaire de tâches.
C’est un besoin différent, et c’est dans beaucoup de cas le seul truc qui atteste de l’avancement d’un projet bien que ce ne soit pas le meilleur moyen de faire avancer un projet d’ingénierie informatique.
Je ne fais donc pas de lien direct entre un service en ligne de client et mes tâches orgmode. Cependant j’ai une section Boulot où je note certaines tâches macroscopiques ou des choses à voir avec des personnes en particulier, car cela n’a pas sa place dans l’outil de tickets des clients mais a du sens pour ce que je fais.
Templates de capture
Voici ma configuration actuelle pour les templates de capture. Cela me sert à créer des tâches horodatées:
– à clarifier
– prévues pour aujourdhui
– prévues pour être faites en prochaine action dans un projet en particulier
– pour le boulot en général
– des emails à écrire
– des appels à faire
– pour noter des choses lors d’une réunion
– pour entrer des notes dans mon journal que je ne tiens pas du tout régulièrement
– pour horodater des évènements
;;; templates de capture pour les nouvelles tâches
(setq org-capture-templates
'(
("t" "Todo someday"
entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox")
"* SOMEDAY %? \n")
("d" "Todo this Day" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox")
"* TODO %?\nDEADLINE:%T \n")
("b" "Boulot" entry (file+headline "~/Nextcloud/textes/orgmode/boulot.org" "Inbox")
"* TODO %?\n :boulot:work: \n\n")
("m" "Meeting" entry (file+olp+datetree "~/Nextcloud/textes/orgmode/reunions.org" "Réunions")
"* Réunion %T - %U \n :[[id:d8636e1d-0137-4502-9384-767b41c892b0][boulot:meeting:]] \n\n**** Gens présents\n**** Notes\n - %?\n**** Choses à investiguer\n -\n**** Prochaines actions\n - Fin de la réunion: \n"
)
("e" "E-mail" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox")
"* TODO %? :mail:écriture: \n\n")
("n" "Next Task" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox")
"** NEXT %? \nDEADLINE: %t \n\n")
("p" "Phone call" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Tel")
"* PHONE %? :tel:\n%U \n\n" :clock-in t :clock-resume t)
("j" "Journal" entry (file+olp+datetree "~/Nextcloud/textes/orgmode/journal.org")
"* %?\nÉcrit le %U\n ")
;; ajouter une ligne dans un tableau
("v" "Table" table-line
(file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Table")
"| %U | %? | auto-capture |")
)
)
;; raccourci custom pour clavier sans pavé numérique
(global-set-key (kbd "C-T") 'org-capture)
J’ai aussi un template de capture pour les réunions que j’utilise pour des entretiens avant de travailler avec les clients. ça m’a servi plus d’une fois pour retrouver des explications très globales au contexte de mission et aux objectifs du projet. Les entretiens préalables aux missions sont riches d’infos utiles une fois que l’on travaille vraiment pour quelqu’un.
C’est aussi un template très utile pour des réunions en visio dans des contextes associatifs, bien que souvent on se mette à disposition un pad de rédaction partagée.
Le corps d’un template pour réunion est comme ceci:
* Réunion machin truc, date et heure de création
** Gens présents
** Notes
** Choses à investiguer
** Prochaines actions
** Fin de la réunion : date
Définir ces points permet de rendre la réunion productive et digne d’intérêt, respectueux du temps des gens, bien que pour certains c’est à l’opposé du concept même de réunion.
Approche mobile least
Prendre des notes sur mobile évite d’avoir à transporter un carnet papier pour noter des choses dès qu’on en a l’idée ou que la situation demande qu’on se rappelle de quelque chose, et évite donc de s’encombrer l’esprit avec des tâches inintéressantes.
Noter les choses et documenter les procédures, même de façon très sommaire en vague liste d’étapes après un titre, est un très bon moyen de permettre de les déléguer à d’autre ou à soi même plus tard, et de rendre visible la charge de notre travail pour des corvées.
Cela est aussi un excellent moyen de s’alléger de la charge mentale et de s’éviter de devoir régulièrement faire des recherches sur le fonctionnement d’un truc ou bien ce qu’on a déjà essayé de faire et qui a échoué.
Mais le mobile est une interface médiocre pour faire des tas de choses du fait de son petit format à côté de nos gros doigts et de son petit écran. Il est bon de faire en sorte de l’utiliser en dernier recours.
Un autre moyen de moins s’en servir est de faire de la messagerie instantanée sur ordi et non sur mobile. Beaucoup de choses consistent à envoyer un petit message à un contact via une messagerie comme Signal, Matrix, ou Télégram, ces deux outils disposent de version bureau ou en page web.
Aménager son temps consiste aussi à pouvoir dégager toute notification et interaction par messagerie instantanée. J’ai fait une commande à lancer quand j’ai besoin de me concentrer, qui termine divers programmes d’un seul coup, son alias en ligne de commande est « oklm ».
Orgzly sur mobile est une bonne option pour noter des trucs à réfléchir un peu plus tard lors d’une revue. Cela permet aussi d’avoir un rappel pour une échéance de tâche qui ne serait pas forcément dans mon agenda, et d’avoir une vue des choses prévues à plusieurs jours dans la semaine.
Syncronisé avec syncthing, j’obtiens de meilleurs résultats de synchronisation entre les fichiers qu’avec nextcloud seul, qui peut demander de temps à autre de résoudre des conflits de synchronisation. Il faut juste prendre deux minutes pour dire à son ordi et à son mobile de causer ensemble, mais ça vaut le coup si on veut avoir la main sur ses données à plusieurs endroits.
Je ne trie pas mes tâches générales par Orgzly, je les saisis dans un fichier séparé de mon fichier principal tasks.org, puis un script par cronjob déplace des tâches dans l’inbox de tasks.org toutes les quelques minutes quand mon ordi est allumé.
Vous n’avez pas besoin de notifications et d’emails sur mobile
Autre astuce, j’évite de gérer des tris de tâches ou de la rédaction par mobile, c’est une perte de temps et contrairement à ce que tout le monde peut vous dire, vous n’avez absolument pas besoin de réagir à un email dans la seconde. Vous n’avez en fait pas besoin d’avoir de notifications en général, ou d’application d’email sur votre téléphone. Essayez d’aller dans vos paramètres pour désactiver les notifications et vous verrez à quel point vous allez améliorer votre qualité de vie et votre capacité à vous détendre, et vous concentrer quand vous en avez besoin.
Envoyez chier les gens aussi.
Dernière astuce vraiment efficace: dites non, vous n’êtes pas au service de tout le monde et votre temps n’est pas infini, dire non c’est aussi savoir poser des limites à votre générosité. Si les gens ne respectent pas votre temps, ils ne méritent pas ce que vous faites de votre temps. Alors apprenez à dire non, vous verrez toutes les conséquences bénéfiques que cela peut avoir. Le futur vous même vous en remerciera grandement.
 Le plus simple nous pour nous faire connaître étant de partager cet article.
Le plus simple nous pour nous faire connaître étant de partager cet article.