Pendant les JDLL à Lyon 2024 j’ai eu le plaisir de lancer une série d’interviews nommé « elles font le libre » pour voir un public un peu plus différent que celui habituel lorsque l’on parle de logiciel libre: des gens qui ne sont principalement pas des hommes et qui font des trucs dans le logiciel libre. C’était l’occasion d’avoir quelques regards sur l’état de l’inclusivité dans le milieu libriste. Merci à celles qui se sont prêté au jeu!
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
La communauté d’OSM prenait plaisir à capturer des photos 360 sur Mapillary jusqu’à ce que la nation du feu attaque. Comment exporter ses photos de Mapillary pour les importer en masse dans Panoramax ? Une épopée qui aura demandé de la rétro ingénierie faite de rebondissements intenses vous sera contée par Tykayn avec quelques astuces pour la capture avec des moyens de locomotion décarbonnés et de l’entraide par delà la barrière de la langue.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
À une époque j’utilisais des feuilles de papier pour gérer les trucs que je voulais faire et avoir la satisfaction de dessiner une coche ou de barrer un truc quand c’était fait. Mais ça s’est vite compliqué quand j’ai vu que c’était très difficile de gérer plein de choses à la fois de cette façon et que des trucs disparaissent au fur et à mesure qu’on tourne les pages. Sans parler des problème de pérennité des cahiers, du manque de recherche ou de filtrage, et pour ce qui est de trier les tâches n’en parlons même pas.
Depuis quelques années, et après avoir essayé moult trucs plus ou moins pratiques et exportables pour les analyser, mes tâches sont rangées dans un fichier tasks.org, qui est un simple fichier texte, dans mon dossier de textes syncronisés. C’est le point de départ de mon wiki personnel plein de notes reliées entre elles.
Pour faciliter l’organisation de tâches je les range d’une façon proche de la méthode para: projet, aires, ressources, frigo. Voici les entêtes de mon fichier principal: * Boulot [/] * Projets [/] * Aires de responsabilité [/] ** Activités quantifiées globales ** Associations ** Corvées ** Feuille de pognon ** Lieux à visiter ** Rédaction de textes, Communication ** Santé et médical ** Social ** Travaux et bricolage ** Vacances ** Personnes * Administratif [/] * Frigo [/] * Inbox [/]
Les crochets avec un slash dedans servent à compter les sous tâches et sont mis à jour à chaque sauvegarde de fichier. Les choses pouvant être souvent placées dans plusieurs catégories à la fois, une bonne astuce est de faire usage de tags ou de paraphrases.
Je capture des idées et des trucs à faire soit sur mobile, soit sur ordi, avec une syncronisation entre mes différents postes de travail, ce qui évite d’avoir à reporter des choses en double dans mon système de gestion de tâches constiuté de simples fichiers textes et d’une mise en forme faite par emacs.
Je pratique de temps à autre ce qui s’approche de revue quotidienne, mais non quotidienne. J’ai essayé de faire des tâches récurrentes pour conserver de bonnes habitudes mais au final cela pollue d’avantage mon agenda qu’autre chose, donc j’ai plutôt marqué ces choses à faire dans les revues peu fréquentes.
J’essaie de faire des revues hebdomadaires, mais sans régularité. Je n’ai pas besoin de passer beaucoup de temps dans mes listes de projets pour les faire avancer spontanément et marquer que plein de tâches ont été faites ou reconsidérées bonnes à jeter entre deux revues.
Pour avoir une synchronisation avec mon agenda NextCloud, j’ai un script cronjob qui prend mon calendrier partagé avec ma femme et le convertit en fichier org, ce qui me permet de voir des évènements en plus dans l’agenda affiché dans emacs.
Je fais aussi en sorte de ne pas utiliser ma boite mail comme un gestionnaire de projet et pratique la méthode Kondo dans mes emails: certains sont à archiver car il se peut vraiment que j’en aie besoin à un autre moment, mais tout le reste n’est que du bruit et a sa place dans un endroit qui ne mérite aucunement mon attention, ils ne sparkent pas la joy, donc hop, poubelle.
J’ai généralement sur mon ordi une instance d’emacs avec mon agenda de la semaine ouvert pour voir à quoi consacrer ma journée.
Les vues filtrées d’agenda sont très utiles pour regrouper des tâches ensemble sur une recherche de mot ou de tag.
Wiki personnel
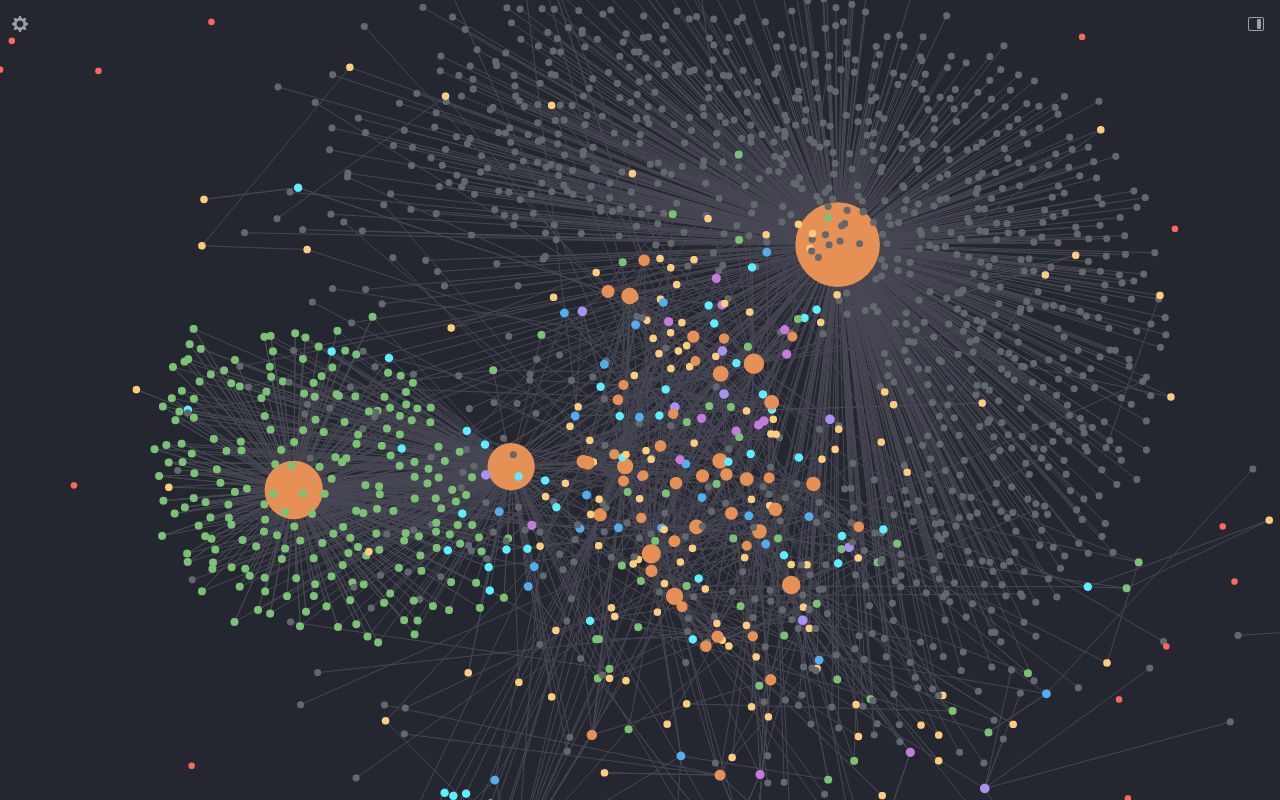
Toujours dans un maillage de fichiers org, j’utilise org roam pour relier mes écrits par liens directionnels. Le package org-roam-ui permet de voir un graphe interactif de ces liens et de stimuler de nouvelles notes, ou de voir des liens, retrouver des écrits, en créer de nouveaux. Pour ce wiki, j’ai une page d’index qui relie différents textes que j’ai exporté de mes blogs, certaines thématiques liées à un paquet d’articles et je tente de temps à autre de relier à des billets entre eux et de dégager des thématiques. Ce genre d’outil visuel est un très bon moyen de mettre en perspective ce que l’on souhaite raconter. Fonctionnalité marrante, org-random-note qui permet d’afficher une note au hasard.
Concilier différents gestionnaires de projet
Certains outils existent pour relier ses tâches orgmode à un service en ligne, mais je ne les ai pas testé. Les choses liées au boulot ont généralement un gestionnaire de projet en ligne séparé de mon gestionnaire de tâches. C’est un besoin différent, et c’est dans beaucoup de cas le seul truc qui atteste de l’avancement d’un projet bien que ce ne soit pas le meilleur moyen de faire avancer un projet d’ingénierie informatique. Je ne fais donc pas de lien direct entre un service en ligne de client et mes tâches orgmode. Cependant j’ai une section Boulot où je note certaines tâches macroscopiques ou des choses à voir avec des personnes en particulier, car cela n’a pas sa place dans l’outil de tickets des clients mais a du sens pour ce que je fais.
Templates de capture
Voici ma configuration actuelle pour les templates de capture. Cela me sert à créer des tâches horodatées: – à clarifier – prévues pour aujourdhui – prévues pour être faites en prochaine action dans un projet en particulier – pour le boulot en général – des emails à écrire – des appels à faire – pour noter des choses lors d’une réunion – pour entrer des notes dans mon journal que je ne tiens pas du tout régulièrement – pour horodater des évènements
;;; templates de capture pour les nouvelles tâches (setq org-capture-templates '( ("t" "Todo someday" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox") "* SOMEDAY %? \n") ("d" "Todo this Day" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox") "* TODO %?\nDEADLINE:%T \n") ("b" "Boulot" entry (file+headline "~/Nextcloud/textes/orgmode/boulot.org" "Inbox") "* TODO %?\n :boulot:work: \n\n") ("m" "Meeting" entry (file+olp+datetree "~/Nextcloud/textes/orgmode/reunions.org" "Réunions") "* Réunion %T - %U \n :[[id:d8636e1d-0137-4502-9384-767b41c892b0][boulot:meeting:]] \n\n**** Gens présents\n**** Notes\n - %?\n**** Choses à investiguer\n -\n**** Prochaines actions\n - Fin de la réunion: \n" ) ("e" "E-mail" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox") "* TODO %? :mail:écriture: \n\n") ("n" "Next Task" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Inbox") "** NEXT %? \nDEADLINE: %t \n\n") ("p" "Phone call" entry (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Tel") "* PHONE %? :tel:\n%U \n\n" :clock-in t :clock-resume t) ("j" "Journal" entry (file+olp+datetree "~/Nextcloud/textes/orgmode/journal.org") "* %?\nÉcrit le %U\n ") ;; ajouter une ligne dans un tableau ("v" "Table" table-line (file+headline "~/Nextcloud/textes/orgmode/tasks.org" "Table") "| %U | %? | auto-capture |") ) ) ;; raccourci custom pour clavier sans pavé numérique (global-set-key (kbd "C-T") 'org-capture)
J’ai aussi un template de capture pour les réunions que j’utilise pour des entretiens avant de travailler avec les clients. ça m’a servi plus d’une fois pour retrouver des explications très globales au contexte de mission et aux objectifs du projet. Les entretiens préalables aux missions sont riches d’infos utiles une fois que l’on travaille vraiment pour quelqu’un.
C’est aussi un template très utile pour des réunions en visio dans des contextes associatifs, bien que souvent on se mette à disposition un pad de rédaction partagée.
Le corps d’un template pour réunion est comme ceci:
* Réunion machin truc, date et heure de création ** Gens présents ** Notes ** Choses à investiguer ** Prochaines actions ** Fin de la réunion : date
Définir ces points permet de rendre la réunion productive et digne d’intérêt, respectueux du temps des gens, bien que pour certains c’est à l’opposé du concept même de réunion.
Approche mobile least
Prendre des notes sur mobile évite d’avoir à transporter un carnet papier pour noter des choses dès qu’on en a l’idée ou que la situation demande qu’on se rappelle de quelque chose, et évite donc de s’encombrer l’esprit avec des tâches inintéressantes.
Noter les choses et documenter les procédures, même de façon très sommaire en vague liste d’étapes après un titre, est un très bon moyen de permettre de les déléguer à d’autre ou à soi même plus tard, et de rendre visible la charge de notre travail pour des corvées.
Cela est aussi un excellent moyen de s’alléger de la charge mentale et de s’éviter de devoir régulièrement faire des recherches sur le fonctionnement d’un truc ou bien ce qu’on a déjà essayé de faire et qui a échoué.
Mais le mobile est une interface médiocre pour faire des tas de choses du fait de son petit format à côté de nos gros doigts et de son petit écran. Il est bon de faire en sorte de l’utiliser en dernier recours.
Un autre moyen de moins s’en servir est de faire de la messagerie instantanée sur ordi et non sur mobile. Beaucoup de choses consistent à envoyer un petit message à un contact via une messagerie comme Signal, Matrix, ou Télégram, ces deux outils disposent de version bureau ou en page web.
Aménager son temps consiste aussi à pouvoir dégager toute notification et interaction par messagerie instantanée. J’ai fait une commande à lancer quand j’ai besoin de me concentrer, qui termine divers programmes d’un seul coup, son alias en ligne de commande est « oklm ».
Orgzly sur mobile est une bonne option pour noter des trucs à réfléchir un peu plus tard lors d’une revue. Cela permet aussi d’avoir un rappel pour une échéance de tâche qui ne serait pas forcément dans mon agenda, et d’avoir une vue des choses prévues à plusieurs jours dans la semaine. Syncronisé avec syncthing, j’obtiens de meilleurs résultats de synchronisation entre les fichiers qu’avec nextcloud seul, qui peut demander de temps à autre de résoudre des conflits de synchronisation. Il faut juste prendre deux minutes pour dire à son ordi et à son mobile de causer ensemble, mais ça vaut le coup si on veut avoir la main sur ses données à plusieurs endroits.
Je ne trie pas mes tâches générales par Orgzly, je les saisis dans un fichier séparé de mon fichier principal tasks.org, puis un script par cronjob déplace des tâches dans l’inbox de tasks.org toutes les quelques minutes quand mon ordi est allumé.
Vous n’avez pas besoin de notifications et d’emails sur mobile
Autre astuce, j’évite de gérer des tris de tâches ou de la rédaction par mobile, c’est une perte de temps et contrairement à ce que tout le monde peut vous dire, vous n’avez absolument pas besoin de réagir à un email dans la seconde. Vous n’avez en fait pas besoin d’avoir de notifications en général, ou d’application d’email sur votre téléphone. Essayez d’aller dans vos paramètres pour désactiver les notifications et vous verrez à quel point vous allez améliorer votre qualité de vie et votre capacité à vous détendre, et vous concentrer quand vous en avez besoin.
Envoyez chier les gens aussi.
Dernière astuce vraiment efficace: dites non, vous n’êtes pas au service de tout le monde et votre temps n’est pas infini, dire non c’est aussi savoir poser des limites à votre générosité. Si les gens ne respectent pas votre temps, ils ne méritent pas ce que vous faites de votre temps. Alors apprenez à dire non, vous verrez toutes les conséquences bénéfiques que cela peut avoir. Le futur vous même vous en remerciera grandement.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
On peut faire des trucs pour le fun, ou des truc moins sympa en étant totalement béats, en nommant bêtement « intelligence artificielle » des tas de trucs qui n’en sont pas.
On peut voir des démos impressionnantes régulièrement, mais n’oublions pas de questionner les intérêts des personnes qui les mettent en avant, et de faire des vérifications régulières avec la réalité pour distinguer le bullshit marketing, les cris au loup, et les réelles implications sur les personnes sans oublier les situations similaires dans l’histoire.
Oui on peut faire marcher des LLM (voir sur wikipédia) sur son ordi portable faiblard, et faire des bouts de code avec une documentation inutile, qui marche à peu près, dans son éditeur de code avec Wholly et Ollama, ou bien chez Huggingchat. On peut s’éviter moult recherches pour assembler des bouts de ficelle entre des paquets comme on le fait habituellement depuis les origines de l’informatique. On peut avoir rapidement des explications sur plusieurs sujets à la fois, faire des calculs de coin de table en ayant son déroulé si on ne fait pas trop gaffe à ce que ça raconte. On peut aussi jouer à fabriquer des images ou redessiner des dessins en espérant que les générateurs d’image ne vont pas converger vers une autophagie qui rendra leurs créations toujours plus fades et semblables, tout en se demandant pourquoi ces fameux générateurs d’image à diffusion de bruit sont incapable de faire des mains et des visages corrects.
On pourrait rechercher à faire disparaitre les boulots à la con et rendre aux gens le temps volé par des emplois inhumains et inutiles, bordés de trajets tout autant inhumains et inutiles pour la majorité, car y’a encore pas mal de boulots qui ne sont pas éligibles au télétravail.
Faire disparaitre des tâches aliénantes, c’était déjà un sujet au début de l’industrialisation et lorsque les métier à tisser faisaient disparaitre des emplois, et qu’émergèrent les fameux luddites, ou que Chaplin visse des boulons dans les Temps Modernes. Les luddites ne faisaient pas que casser des métiers à tisser, ils souhaitaient surtout réfléchir à comment faire société dans un contexte où il n’y avait soudainement plus besoin d’avoir autant de gens qu’avant pour faire un même produit, voire, un produit de meilleure qualité, à une époque où Le Capital décrivait déjà la scission entre les personnes propriétaires des moyens de productions et ceux qui avaient la force de travail pour assurer la production tout en étant à la merci des détenteurs du fruit de leur travail, les fameux capitalistes qui concentrent les titres de propriétés et les différentes richesses, dont notre modèle de société s’inspire dans sa version tardive avec une extension de ce qui est inclus dans des marchés sur toujours plus d’aspects de la vie de tous et toutes, jusqu’à capitaliser le temps d’attention et avoir engendré une économie de la surveillance qui produit un environnement contrôlant les individus jusque dans leur intimité, aux conséquences désastreuses sur bien des aspects de la vie en plus de pérenniser les dictatures et faire durer les guerres. Ce sont des points importants à considérer quand on voit la montée de partis ouvertement facistes, qui n’ont jamais changé de cap dans leurs votes hostiles au plus démunis, qui parlent tranquillement de déporter des étrangers en 2024, ou de pouvoir faire des loi sans avoir à s’ennuyer de leur constitutionnalité ou de ne pas se laisser emmerder par les médias ou les contre pouvoirs, et ce depuis leur création par des gens nostalgiques du 3e Reich, comme le rappelle Clément Viktorovitch.
Beaucoup n’avaient pas vu venir la prédation de loisirs ou de jobs créatifs par des LLM, on imaginait surtout que ce genre d’outil permettrait de se passer de travaux pénibles et dangereux pour la santé. Mais on aime mélanger robotique et génération de texte, ce n’est pas propice à une compréhension de comment émergent ces outils. Sans oublier que le marketing est précisément là pour faire croire qu’il y a plus de choses nouvelles qu’il n’y en a réellement, et que vous êtes une sombre merde si vous n’achetez pas cela, car seul la hype culpabilisante qui fait vendre est intéressante.
On pourrait envisager la pérennité des outils en utilisant des modèles de langage aux licences Creative Common, entrainés sur des corpus de données dont la qualité et la sureté ont été vérifiée et est disponible pour les réutilisations, capables de fonctionner hors ligne avec de petits moyens de puissance de calcul, ou bien avoir des outils mutualisés capables de travailler ensemble par des standards d’interopérabilité. Ces choses existent, oui. On a vu émerger des améliorations sur des calculs existants utiles à la recherche, oui. Ce n’est pas parce que vous avez un clavier que vous savez taper à plus de trois doigts et sans le regarder, ou qu’il existe des dispositions ergonomiques très adaptées au français et à l’anglais et à la programmation bien mieux que l’azerty que vous avez toujours connu, que vous pratiquez l’optimot, le bépo, ou l’ergol. Non, comme toujours, ce que l’on utilise est le résultat d’un ensemble de tendances dominantes qui vont se cacher jusque dans nos goûts pour telle ou telle chose, dont on ne mesure pas du tout l’étendue et à quel point on cherche constament à se situer par la distinction comme l’a théorisé un certain Bourdieu.
Que l’on soit libriste, zététicien, sociologue ou féministe, ne permet pas de voir toutes les erreurs de jugement au moment où on les fait, cela permet au contraire de gagner en humilité et de voir à quel point on est le résultat d’un ensemble de choses que l’on a pas choisi.
On peut essayer de faire advenir ce qui se passe dans le film Her, tel qu’on le voit se profiler cette année avec l’interface vocale et visuelle de GPT4o (que l’on pourrait combiner à un avatar animé comme le font les Vtubers) ou dans la série coréenne Holo, ou encore dans le film l’homme bicentenaire où on peut voir toute l’évolution de ce qui ressemble vaguement à une intelligence artificielle qui évolue avec l’aide d’humains pour devenir officiellement assez semblable aux humains pour obtenir des droits égaux. Les options sont nombreuses, de Wall-E à Altered Carbon ou à un monde sans scarcité où l’on a inventé des Printeurs.
Chacune de ces fictions éclaire un avenir plus ou moins désirable où l’on est plus ou moins désaisi de notre capacité à coexister avec des machines que l’on aurait du mal à considérer de la même façon que l’on considère un grille pain tant elles font très bien comme si elles étaient comme nous, et cela met en perspective également la façon dont on tolère les structures de domination déjà existantes entre les humains qui déshumanise totalement une bonne partie de la population. Et je ne parle pas des captchas qui nous font douter de notre humanité.
On est encore loin de la fameuse « fin du travail », et il pèse sur l’avenir la menace bien plus tangible de celle des conséquences du changement climatique provoqué par l’humain que celle de Terminator. Mais comme toujours, ce n’est pas parce qu’on a des outils capables de faire des trucs assez dingues que cela va bénéficier au plus grand nombre d’un coup de baguette magique, surtout lorsque l’on fait en sorte que le plus grand nombre soit un consommateur passif des technologie en lui empêchant totalement d’avoir du contrôle dessus, ou de pouvoir apprendre comment cela fonctionne. Mais cela fait des centaines d’années que le problème n’est pas un sujet, tant il semble plus important que l’on emploie le peuple à l’asservissement de quelques uns plutôt que de se demander comment faire en sorte que tout le monde puisse vivre mieux en dehors d’un emploi ad vitam alors que c’est de plus en plus techniquement faisable. Certains politiciens s’aventuraient à reconnaître que l’emploi est inadapté, tel Obama qui disait en 2008 « bien sûr qu’on a pas besoin d’autant de gens pour que les banques fassent ce qu’on leur demande de faire, mais si on se débarrassait de tous ces jobs inutiles, qu’est ce qu’on ferait de ces gens? ». Cela fait très longtemps qu’il semble inconcevable que de plus en plus de gens puissent vivre comme les grands bourgeois, ou tout du moins, sans aller dans la démesure des grandes fortunes, à être propriétaire de leur temps. C’est d’ailleurs parfois assumé qu’il faille tout faire pour que « les gens » soient toujours occupés, sinon ils commenceraient à s’organiser et à se rendre compte que nombre de choses désagréables qu’ils vivent sont le résultat de décisions inhumaines, prises par des gens qui sont semblables à eux, et que mis à part quelques papiers qui disent que les choses doivent fonctionner comme cela, il n’y a aucune raison de vivre autant de peines pendant toute leur vie? Pire encore, ces dominations sont entretenues, reproduites, et mise en marche avec un monopole de la violence légitime, actée par des semblables qui sont pourtant tout autant victimes de cette domination. Ce n’est pas un hasard si les dominations perdurent ainsi, c’est le résultat de décisions politiques et de barrières de pouvoir organisées par des humains contre d’autres humains. Mais ce n’est pas une fatalité. Croyez vous que l’invention du vélo ait amélioré la vie des chevaux?
What will we do when humans need no apply? par CGP Grey.
C’est assez difficile d’avoir des informations dépassionnées sur tout ce qui tourne autour de l’IA tant de nombreux marketteux survendent le truc et que lorsque l’on cherche à en savoir plus on tombe assez vite dans un gouffre entre technobéatitude ou vulgarisation très superficielle que l’on croise dès que l’on s’approche d’un sujet qui dispose d’une vraie complexité technique et d’une littérature fantastique.
J’ai cherché à développer des intelligences algorithmiques pour un jeu vidéo de combat en 2002, puis j’ai cherché à automatiser des choses en développant des petits trucs, à tirer du sens de corpus de textes, à trouver des choses dans des images, à tenter de faire fabriquer des blagues par de petits scripts, à travailler dans l’analyse de sondages et à développer professionnellement des trucs divers et variés depuis 2008, mais je n’aurai pas l’indécence d’aller prétendre que je développe des IA quand je présente un graphique qui montre combien on a de sous en banque. Je ne peux pas dire que j’ai une grande expérience dans l’apprentissage profond, mais j’ai suffisamment lu et vu de choses sur l’histoire de la recherche scientifique autour de l’intelligence artificielle et notamment ses échecs pour voir de nombreuses arnaques intellectuelle sur le sujet, qui persitent encore aujourdhui.
L’IA ce sera une révolution le jour où cela permettra de rendre aux plus démunis les moyens d’avoir des revenus décents, de ramener des services publics, de sortir de l’autosolisme et des énergies fossiles, aux séniors d’avoir des soins en vivant hors des villes de plus de 100 000 habitants, aux étudiants d’avoir de quoi bouffer, aux élus d’être plus de 0.57% a avoir déjà travaillé dans leur vie, de pouvoir manger pas que des choses ultra transformées sans consacrer la moitié des terres agricoles à nourrir des bovins, d’éviter aux femmes de connaître des agressions sexuelles toute leur vie, de décarboner l’ensemble des activités humaines et améliorer la vie de toutes celles et ceux qui subissent des mécanismes qui les empêchent d’espérer autre chose qu’une vague survie dans une vie d’épuisements et de chacun pour soi.
Certains croient que c’est parce que l’on manque d’informations que des politiques hostiles aux humains sont mises en place, et que donc seule une IA serait neutre et capable d’agir pour sauver tout le monde. Mais c’est se fourvoyer sur tous les tableaux avant même de réfléchir à la problématique d’alignement des intentions quand on confie du pouvoir à un acteur, quel qu’il soit, et pas que l’empreur Palpatine qui « aime la démocratie » lorsqu’elle lui confie les pleins pouvoirs en réponse à la peur de l’assemblée.
Ce sera un énorme progrès quand une IA sera capable de nettoyer vos chiottes, d’éviter l’évasion fiscale patronale, de faire reculer la peine de mort, de permettre que la recherche scientifique ne soit pas parasitée par des éditeurs, que des gens ne meurent pas de maladies que l’on sait déjà soigner mais qui sont embrigadés dans des dérives sectaires anti-science, les mêmes qui empêchent de faire des actions pour empêcher le réchauffement climatique alors que, répétons le, les solutions sont connues.
Ce sont les actions qui manquent, bien qu’elles soient mises en place et qu’il ne faudrait pas invisibiliser les travaux de nombreuses personnes qui font avancer la connaissance du modèle climatique et ses nombreuses composantes, il faudrait sérieusement se bouger pour transformer nos sociétés sans juste dire des bêtises aux gens en leur faisant croire qu’il suffit que chacun efface ses emails et jardine dans son potager pour subvenir à ses besoins, tout en les aidant à cramer du pétrole avec une aide à la pompe plutôt que de faire en sorte que la majorité des gens ne soit pas dépendant de cela pour se déplacer ou se chauffer, et qu’il faudrait pas embêter les gouvernements à faire des politiques nationales un peu trop efficaces hein. Vous ferez bien de la sobriété en ne mangeant qu’un jour sur cinq. Oui, c’est plutôt comme ça qu’on communique sur comment éviter les catastrophes en 2024. L’idée n’étant pas de se dire qu’il faut faire peur et de faire paniquer tout le monde, cela donne de très mauvais résultats sur le plan des motivations à agir. Bien que l’on ait de sérieuses raisons de craindre les conséquences d’une poursuite de notre façon de nous déplacer, nous nourrir, nous chauffer, travailler « comme si de rien n’était » alors que les prédictions sur les dégâts humains et notre environnement semblent plutôt bonnes depuis 1970, voire pas assez pessimiste depuis 2010. Sans oublier que les effets rebonds existent, surtout quand il y a de la hype dans le grand public. À modérer cependant, certaines conséquences sont contre intuitives, surtout si vos sources d’informations sont habituées à dire du mal de la science en général et à faire des appels au « bon sens » et à la bonté de la nature. Alerte rouge, surtout si on vous incite à remplacer des choses qui n’ont pas ou très peu d’effet sur le potentiel de réchauffement global, par des choses qui en ont 10 ou 100 fois plus. Autre point d’attention, si quelqu’un mélange n’importe comment électricité et énergie en faisant comme si la seule énergie que l’on utilise est électrique, c’est mauvais signe et très éloigné de la réalité, même si on ne regarde que ce qui se passe en France. Jouez au jeu « qui est l’expert », s’exprime il dans son domaine d’expertise, est il capable de citer une source produite par quelqu’un d’autre (et pas juste une ONG qui produit des rapports avec des infos sorties de son cul), et surtout, « est il reconnu par d’autres de son domaine comme quelqu’un de compétent ».
Concernant l’IA telle qu’on nous la vend aujourd’hui, il est prévu que lui soient dédiées de nouvelles capacités de production d’électricité. La décarbonation de l’électricité dans le monde progresse mais pas super rapidement (on a beau mettre en ligne des éoliennes et du solaire tout les jours), cela veut donc dire que les sources de production fossiles, hautement impactantes sur le réchauffement global et polluantes de plusieurs façons, vont devoir être d’avantage utilisées en attendant. Alors certes, les financements de nouvelles installations sont encouragées surtout pour décarboner les productions d’électricité, mais il ne faut pas oublier que tant que ces nouvelles capacités ne viennent pas supprimer des productions qui crament des fossiles on n’éloigne pas du tout la catastrophe. Oui, c’est étonnant, mais dans beaucoup de cas un déploiement massif d’énergies propres n’enlève pas les saloperies fossiles, alors que cela devrait être la priorité.
Autre point important, les gouvernements sont prévenus depuis des années qu’il faut renforcer les réseaux électriques pour accueillir les nouvelles capacités électriques décarbonnées, et qu’il va falloir du stockage pour pallier les intermittences du vent et du soleil, avec de l’hydro serait une excellente idée. Mais croyez vous que les gouvernements se hâtent de réaliser de nouvelles STEP hydro ou de lancer des travaux de rajout des 1% de capacité tous les ans demandés par RTE d’ici 2030? Que nenni. On est encore et toujours emmerdés par des inactions politiques, qui préfèrent se soucier de comment rester en selle et faire plaisir à leurs copains en démontant des services publiques plutôt que de planifier des choses qui pourraient pourtant flatter leur égo de sauveur du monde.
Autant vous le dire toute de suite, ça ne va pas être facile et se faire en un claquement de prompt, et ce ne sont pas les rapporteurs des rapports du GIEC qui vous diront le contraire. On peut résumer le problème comme ceci:
si vous ne prenez pas sérieusement le sujet du réchauffement climatique pour l’empêcher, vous n’aurez rapidement aucun autre problème.
« L’avantage de ce champignon, c’est qu’il te nourrit jusqu’à la fin de ta vie ». Fun fact, les guides pour manger des champignons contiennent de nombreuses anneries, même ceux publiés de nos jours, et l’OMS recommande d’ailleurs de ne pas manger de champignons, mêmes ceux qui sont parfaitement comestibles plus d’une fois par jour car des tas de gens ne supportent pas leur très très faible toxicité.
Si vous découvrez le sujet du changement climatique (ou que vous viviez dans une grotte pendant les 10 dernières années, how dare you?) vous pouvez commencer par mesurer l’étendue des dégâts et mesurer votre empreinte en équivalent carbone chez Nos GEStes climat, et la comparer à celle nécessaire à la survie sur terre en 2050. Ou planifier des voyages dans le monde en comparant des moyens de réduire au maximum leur empreinte sur Low Trip. Coucou le train, les voiliers, les sous marins nucléaires (heu bof en fait :D).
Ça pourrait vous aider à prioriser vos actions en ayant une idée un peu plus précise de ce qu’il convient de faire pour soi et pour la collectivité pour avoir une chance d’avoir d’autres problèmes à régler dans quelques années.
En bonus, Benjamin Bayart qui lui a fait sa thèse de fin d’étude sur les réseaux de neurones et l’intelligence artificielle pourra vous dire ce qui rentre ou pas dans le bullshit, et à quel point peu importe l’outil tant qu’on ne questionne pas ou que l’on masque la volonté politique de nuire et les biais qui l’accompagne.
Havez fun!
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
Récupérer ses photos de plateformes non libres, GAFAM, mapillary et kartaview
Demandez vos archives
le RGPD impose aux géants du ouaib et aux autres de permettre la ciculation des données aussi bien que de l’épice, vous avez donc des trucs qui vous permettent de demander vos données photos. Il faut juste fouiler dans votre compte utilisateur et ne jamais partir du principe qu’un hébergement en ligne est synonyme d’éternité ou de fiabilité absolue. Faites des sauvegardes automatiques, ça vous évitera bien des ennuis et il est inéluctable que les supports de stockage et les hébergeurs meurent un jour.
Récupérer ses photos de Kartaview
Quand Facebook a acheté Mapillary, on a vu venir le merdier et de bonnes volontés se sont empressées de faire des outils en ligne de commande ou en page web pour exporter nos captures plus ou moins facilement. Certains se sont dit qu’il serait mieux de migrer leurs photos vers OpenStreetCam, qui s’est fait racheter par une compagnie de taxis chinoise, Grab, qui a rebaptisé le produit Kartaview. OpenStreetCam n’a jamais eu une appli très utilisable, Kartaview a amélioré cela mais l’export massif de photos n’a jamais été une priorité pour la boite, il n’y a pas d’API pour cela aux dernières nouvelles en 2023. Cependant, si on leur demande par email ils veulent bien que l’on accède au stockage (avec un délai de réponse d’environ 10 jours).
Si vous voulez voici ce que je leur ai demandé à geo.kartaview@grabtaxi.com:
Hello, i would like an archive containing all my pictures in hi resolution, can you send me this please?
Here is proof i am the owner of my account: [votre pseudo] Level [x] Total points [x] Points to next level [x] Tracks: [x] Distance: [x] km Distance with OBD: [x] km
have a good day.
– [votre pseudo]
Au bout d’une semaine ils m’ont donné des instructions pour accéder au stockage de mes captures, qu’ils hébergent chez Microsoft. Puisque les informations de géolocalisation sont séparées des photos, j’ai du faire un script pour les rabouter ensemble. Voici de quoi faire de même si vous le souhaitez: https://forge.chapril.org/tykayn/scripts/src/branch/master/kartaview_exif_mapper
Récupérer ses photos de Mapillary
Y’a là aussi pas de moyen d’exporter vos photos juste en téléchargeant un zip depuis votre espace utilisateur, ce serait trop simple et trop conforme au RGPD ou à la précédente loi informatique et libertés.
Je leur ai aussi demandé par écrit, par mail, mais là seul le mistral m’a répondu et on dirait bien que la CNIL n’en a cure.
Ce script fonctionne pour télécharger vos séquences mais aussi celles d’autres personnes, veillez simplement à avoir un accord écrit des autres gens si vous souhaitez le faire.
Les alternatives existent, beaucoup de choses stratégiques sont perdues du fait d’un manque cruel de souveraineté nationale des outils et des données. Les alternatives existent et ne sont pas plus compliquées à utiliser que les plus connues.
Go go go! Envoyez sur Panoramax avec votre compte OpenStreetMap, des tas de trésors photos dorment dans les placard de la NSA, faites en profiter le grand public au lieu de n’alimenter que des trolls, surtout si vous êtes partie prenante dans un service public.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
Il faut fouiller dans les paramètres d’open camera (disponible sur f-droid) pour régler les config, c’est l’icône roue dentée en haut à droite:
– Activer le GPS du smartphone. Et enregistrer les infos GPS dans les photos: Paramètres > Paramètres de géocodage >✅ Stocker les données de position + ✅stocker la direction de la boussole.
– Plus de paramètres > préfixe du nom de photo « IMG_OC_ » afin de retrouver facilement ses photos de séquence de capture parmi ses photos perso, à prendre avec une autre appli de photo. C’est optionnel.
L’icône trois points verticaux (buger menu) à côté de la roue dentée vous permet d’accéder à des raccourcis de config:
– Faire la mise au point à l’infini, première ligne d’icones, symbole infini ∞.
– Désactiver le flash si présent.
– Mettre le mode rafale, et régler en rafale infinie. Icone []]] ou sélecteur Mode rafale: illimité. – Mettre un délai de retard de prise de vue pour espacer la rafale de 1 ou quelques secondes. ça dépend si on marche ou si on utilise une ventouse ou un accessoire vélo pour tenir le smartphone. astuce bonus: ajouter un préfixe aux noms des photos pour distinguer nos photos servant de captures pour panoramax des photos prises pour soi.
Vérifiez bien que vous capturez avec une très bonne résolution d’image.
Enfin, pour l’envoi vers Panoramax on peut utiliser le site ouaib, avec votre compte OpenStreetMap, pour balancer vos photos copiées depuis son smartphone. https://panoramax.openstreetmap.fr
L’appli Wifi File transfert peut être d’une grande aide si le transfert par cable USB est capricieux avec votre tel 😉
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
Un jour, j’ai voulu voir à quel point OSM était à jour concernant les bornes de recharge électrique, et ce qu’il existait comme jeu de données à disposition. C’est alors que je me suis lancé dans un recensement, puis dans la lecture du wiki concernant les bonnes pratiques à propos de l’intégration de jeux de données ouverts.
voir qu’Enedis se vante d’avoir raccordé 110 000 points de charge à l’été 2023, mais que l’open data n’en comporte que 44 000, soit moins de la moitié. Le Gireve est censé réunir les infos, mais rien n’est ouvert par défaut. Cet organisme n’a jamais souhaité publier de jeux de données au public. L’association OSM France en a fait la demande pour en discuter dès 2015 mais n’a jamais obtenu le moindre entretien.
fouiller les jeux de données à utiliser. trouver des tas de liens morts dans des sites de documentation sur l’open data.
voir l’existant du boulot déjà réalisé et de la documentation à disposition concernant les bornes de recharge, la correspondance attendue entre les données ouvertes et les tags OSM. La conversion du fichier de données qui liste des points de charge et des stations de recharge par Jungle Bus / nlehuby. France/data.gouv.fr/Bornes de Recharge pour Véhicules Électriques – OpenStree…
fouiller les libs utilisées habituellement par les personnes dont la data scionnnnce est le métier. me décider à opter pour de la bidouille très lisible et commentée en nodejs àpartir de fichiers geojson.
découvrir qu’il est archi courant que les données ouvertes soient d’une piètre qualité, les témoignages de gens qui ont déjà bossé avec depuis longtemps en attestant. C’est assez incroyable à quel point les jeux de données sont produits sans cohérence (et de plein de façons pourries différentes) comparé à ce qui en est attendu, même quand la documentation et qu’un outil de validation sont mises à disposition. Il semble qu’ils soient produits par des tas de gens différents, mais visiblement pas des gens à l’aise avec l’informatique, qui font des tableaux dans des poweurpouaint et les envoient en screenshot dans un pdf. C’est assez impressionant d’amateurisme et étonnament compliqué.
espérer que ce ne sont pas les mêmes énergumènes qui sont aux commandes pour ce qui concerne les choses stratégiques à la survie des gens du pays.
trouver une procédure qui permette de n’ajouter que des informations dont on peut estimer qu’elles sont bonnes en s’inspirant des analyses faites par Osmose.
créer un compte dédié à l’intégration: Bender l’importateur.
faire un essai de conflation sur un seul point de recharge avec succès.
jouer avec OpenRefine et le jeu de données conseillé.
recevoir direct un commentaire qui me fait remarquer que cette contribution est pas terrible.
s’apercevoir que j’ai ajouté des tags qui n’ont rien à voir avec les tags osm, mettre encore moins d’informations dans les données à ajouter.
constater avec horreur que même les valeurs censées être booléennes ne sont pas cohérentes avec des variations dans la casse, des fois true/false, et des fois 1 ou 0.
développer des scripts pour sonder la saleté du jeu de données en rapportant des valeurs uniques par colonne, et en sortir un fichier utilisable dans l’éditeur JOSM pour comparer visuellement les données disponibles dans OSM dans deux calques différents.
aller à la pêche aux infos auprès de gens qui sont censés libérer les données mais qui font tout pour ne surtout pas remplir leurs obligations, en faire état aux autres gens qui cherchent à faire avancer les choses sur le sujet.
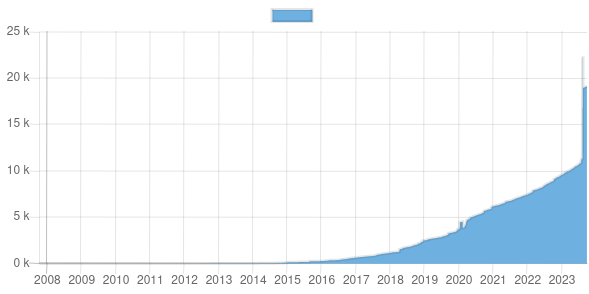
s’apercevoir qu’il manque près de 90 000 points de charge à la publication malgré une loi qui prévoit des sanctions à hauteur de 300€ par point de charge non publié.
avoir une procédure d’ajout de point avec un minimum d’informations valables.
faire des ajouts en comparant visuellement avec les points déjà présents dans JOSM, faire de la sélection au lasso, valider les données dans un calque « à envoyer ». Bien regarder que les nouveaux points de charge ne contiennent rien de bizarre, et zou.
faire progressivement des ajouts sur des zones de plus en plus grandes.
découvrir une option dans JOSM pour sectionner automatiquement les ajouts en plus petits envois pour faciliter le suivi des modifications par zone.
and vouala, en environ 5 jours, 11 000 points de charge ajoutés à partir du jeu de données nettoyées.
fouiller des outils libres sur le sujet des IRVE. Voir le projet cleanfrenchirve qui fait un suivi et nettoyage quotidien du jeu de données de data gouv.
https://github.com/BastienGauthier/clean_french_irve constater que l’open data a supprimé plein de points de charge « pour cause de dédoublonnage », le jeu de données IRVE sur data gouv comporte maintenant environ 20 000 points.
voir que plein de gens ont détecté des coordonnées de bornes inexistantes ou totalement aux fraises dans pas mal de cas.
avoir la joie de voir pas mal de contributeux s’emparer du sujet et faire croitre la quantité et qualité des données.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
faire fonctionner un serveur web express / node pour afficher un compte rendu HTML interprêtant un fichier json représentant des tâches orgmode exportées à partir d’ox-json dans emacs. pour le lancer: npm start.
convertir des exports de services numériques en fichier tsv et json, afin d’être utilisé par les autres parties pour en faire un compte rendu en html.
un convertisseur de site wordpress vers orgmode. La source est un export au format json de la table des posts d’un site wordpress, réalisé dans un client de base de données comme phpmyadmin ou un IDE tel que PhpStorm.
Configuration Vérifiez les variables de chemin dans parse_orgmode_to_json.mjs, surtout outputAbsolutePath pour avoir un lieu de génération de fichier.
Le format de sortie n’est pas le même que celui du parseur org-json par défaut d’emacs, j’y ai ajouté aussi des statistiques sur les tâches avec différents agrégats de durée donnant les nombre et les sortes de tâches.
Des statistiques
Les nombres et le type de tâches agrégées par semaine, mois et années.
le nombre de tâches avec une date.
le nombre de tâches sans date.
la date de la tâche la plus ancienne
données agrégées
Les nombres de fois que des tags sont utilisés dans les tâches.
Les nombres de fois que des mots sont utilisés dans les tâches.
des données sur l’auteur, la date de génération du json, le fichier source .org ayant servi à la conversion.
voir le rendu Lancer l’exécution du fichier app avec node, et consulter l’output html. bash npm start
Memacs
Les scripts inspirés de Memacs (le package python-pip) sont dans le dossier converters, ils permettent de convertir des fichiers exportés de divers outils numériques en feuilles de calcul pour avoir un historique général d’activités simple à lire pour les humains, et facile à analyser pour d’autres scripts.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
C’est pas le tout d’avoir de la belle imagerie 360 avec sa gopro et d’en assembler les deux côtés avec un truc libre nommé fusion2sphere, ce serait bien que ça soit tagué comme le reste des fichiers pour pouvoir les retrouver facilement, tout en ne détruisant pas les séquences en renommant les fichiers.
Il existe justement un script pour ça issu de ma cuisine: gopro_rename.
mettez ce script dans un dossier où votre variable PATH pourra le trouver, puis ouvrez votre terminal préféré. Allez ensuite dans votre dossier de photos gopro qui auront leur nom séparé en fonction de leur côté front ou back, et de leur numéro de séquence.
Vous aurez ainsi un ensemble de fichiers homogènes qui vous permettent de faire des recherches sur leur date de capture.
Vous pourrez ensuite vous amuser à faire du appendfilename ( avec ou sans l’option –smart-prepend) pour ajouter une description aux fichiers correspondant à votre séquence.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
En cherchant un bon outil pour gérer mes projets j’étais tombé sur le fameux GTG: Getting things gnome, un outil local pour gérer des hiérarchies de tâches très rapidement avec une interface graphique de qualitay, mais qui souffre d’un trop grand nombre de fenêtres ouvertes assez rapidement.
ça m’a servi pendant un moment, et puis j’ai ensuite voulu migrer mes quelques 300 tâches et idées vers des fichiers Orgmode, il me suffisait d’écrire un petit convertisseur de fichier de données et tadam!
Les données de GTG sont stockées dans le dossier ~/.var/app/org.gnome.GTG/data/gtg dans des fichiers xml.
Il suffit d’utiliser une lib pour parcourir ces fichiers, récupérer les informations sur les tâches, et en faire des simples textes présentés avec la syntaxe Org dans un nouveau fichier texte. J’ai utilisé un script bash et un autre en nodejs pour cela.
ça a fonctionné très bien pour me rendre compte à quel point utiliser Orgmode dans Emacs est bien plus pratique. Je me disais que ça servira sans doute à d’autres qui veulent tenter de se mettre à Orgmode sans faire exploser leur Getting Things Gnome pour autant, enjaillez!
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.

 Le plus simple nous pour nous faire connaître étant de partager cet article.
Le plus simple nous pour nous faire connaître étant de partager cet article.