Pour ranger mes archives photos selon une organisation par tags dans les noms de fichiers je me suis heurté à une organisation de mes photos qui avait des informations d’évènements situées dans le nom de dossier qui les contenaient. Pour avoir cette information dans le nom de fichier j’avais quelques options: – créer un calendrier à partir de l’arborescence des fichiers et relier ensuite les informations de date d’évènement avec les dates exif de fichier. Pour ça on peut utiliser la commande « tree » qui dessine une arborescence des dossiers. Il suffisait de rediriger la sortie de commande vers un fichier texte pour archiver ces informations dans mon système d’archives. – parcourir les dossiers, prendre l’information du nom du dossier et la placer dans le nom des fichiers. C’est de là qu’est né le petit script python « rename file folder » que j’ai ensuite invoqué derrière un alias à lancer dans mes dossiers d’archive.
Vous pouvez voir la source du fichier python qui permet de renommer les fichiers ici:
ajoutez un alias dans votre fichier ~/.bash_aliases
alias rff="python $WORKFLOW_PATH/files_management/rename_photo_folder.py"
et voilà
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
Aujourd’hui est un grand jour pour la Fédération des pros d’OSM dont CipherBliss fait partie, nous publions officiellement le lancement de la fédé via ce communiqué de presse. Nous existons, et nous sommes actuellement 13 entreprises mettant à disposition leur expertise pour répondre à vos besoins professionnels en matière de prestations liés au géo commun OpenStreetMap. Nous souhaitons promouvoir la souveraineté numérique et le cercle vertueux de l’écosystème d’OSM, en contribuant et en utilisant des logiciels libres au bénéfice de votre entreprise ainsi que dans nos services publics.
La fédération a pour ambition de structurer la filière en mettant en valeur les expertises, réalisations et partenariats de ses membres, en augmentant la visibilité d’OSM auprès des utilisateurs professionnels et pourra servir d’interlocuteur pour des projets d’envergure. Face aux problématiques de souveraineté numérique et de maîtrise des données, OSM apporte des solutions d’innovation ouverte avec un potentiel énorme pour les entreprises et collectivités.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
N’étant pas très ravi de la fonction d’export en JSON native d’Emacs, j’ai créé un parser en nodejs qui produit des statistiques en JSON. il suffit de faire un make convert dans un clone de ce dépot. Modifiez le chemin vers vos fichiers orgmode dans le Makefile.
Vous aurez un beau json qui contient vos tâches, ainsi qu’une partie statistiques détaillant les tâches crées et cloturées sur différents intervalles de temps.
Si vous voulez tester à partir d’un export json de l’exportateur par défaut, c’est aussi possible, il faudra lancer le projet après avoir copié dedans votre export json, et faire un npm start pour voir sur un serveur local une feuille d’activité html.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
Comment communiquer avec ses proches ou des inconnus, de façon vraiment sécurisée par défaut, sans se faire pister en permanence par des entreprises qui asservissent l’humanité, sans avoir à être un fondu de la ligne de commande, et que ça soit utilisable au quotidien ?
La mode qui passe
Selon Stéphane Bortzmeyer, bien que les gens semblent coincés dans l’utilisation d’un logiciel en particulier pour communiquer, les modes passent et les gens s’inscrivent massivement à un nouveau truc plein de paillettes tous les cinq ans environ. Ce ne sont pas les propriétés des logiciels qui sucitent la mode, comme le fait qu’ils soient facile a utiliser, beaux, pratiques, gratuits, permettant de s’envoyer des gifs, de faire de la visio conférence a cinq cent à la fois, hé non. c’est parce que des gens influent ont fait croire à suffisament de monde que ça valait le coup, pour qu’émerge un effet de réseau.
L’effet de réseau (ou rarement effet-club) est le phénomène par lequel l’utilité réelle d’une technique ou d’un produit dépend de la quantité de ses utilisateurs. “J’y suis et j’y reste parce que tout le monde est là”.
Ou plus précisément, j’y suis jusqu’à ce que quelqu’un d’assez influent sur moi m’ordonne de le suivre ailleurs. C’est pénible à reconnaître, mais dans nos fréquentations, certaines personnes vont avoir une posture hiérarchique sur nous, et nous sur eux. Il est clair que pour certaines personnes avec qui on communique, il est très facile de les convaincre de n’importe laquelle de nos convictions et leur faire adopter une pratique similaire à la notre pour beaucoup de sujets, pour d’autres cela relève de la mission impossible, et pour encore d’autres ce sont eux qui nous font changer de comportement sans que l’on se sente légitime à remettre en cause cette domination. Le mot fait peur, mais c’est une réalité.
Ainsi, lorsqu’un service basé sur le capitalisme de surveillance (théorisé par Shoshana Zuboff) obtient un effet de mode, il devient cool de faire la promotion de ce service et de se porter garant de sa communication en criant à qui veut bien l’entendre qu’on a un compte dessus, comme si la coolitude du dit service était aussi un peu la nôtre, de la même façon que l’on partage son engouement à soutenir un club de sport. On ne soutient pas un membre en particulier, mais une équipe, quand bien même cette équipe ne comporte plus une seule des personnes de l’époque où on l’a connu. On a alors une approche dogmatique de ce qu’il convient de suivre et la remise en question du dogme devient difficile au fur et à mesure qu’on en fait la promotion en demandant de ne pas le remettre en question. Bref, on se tire une balle dans le pied quand on soutient une cause si on ne nous autorise pas à la comprendre ou a la questionner.
D’un autre côté, pour gérer leur identité en ligne, beaucoup de gens ont toujours en usage une ou deux très vieilles adresse e-mail, créé il y a fort fort longtemps avec un mot de passe tout pourri de 5 caractères et un chèque en blanc au fournisseur d’e-mail pour tout savoir de nos communications et de notre graphe social. C’est le cas pour Gmail mais aussi pour n’importe quel fournisseur d’e-mail qui ne pratique pas par défaut un chiffrement intégral et de bout en bout.
Des boites comme Protonmail ou Tutanota le font de façon ultra simple pour les utilisateurs, tout en gagnant leur pain avec des abonnements et des donations. Des gens qui s’auto-hébergent peuvent aussi le faire sur leur propre ordinateur, mais c’est long, difficile et demande beaucoup de montée en compétences. Dans thunderbird il existe l’extension Enigmail qui permet de faire les choses plutôt facilement, mais là aussi ce n’est pas par défaut. L’e-mail reste la base de l’identité numérique sur le web et c’est bien souvent la première chose qu’on vous demande pour créer un compte quelque part. Comme tout le monde a au moins une adresse email, ça pourrait servir à communiquer.
De ce fait, fournir une identité qui vous permet de vous connecter a un site “via” un autre pour lequel vous avez déjà un compte, devient un grand atout face à la flemme. Google et Facebook l’ont bien compris et fourni de quoi faire en sorte de se connecter à des millions d’autres sites via leur Single Sign On, qui leur permet de savoir et de contrôler qui se connecte à quoi, et comment.
Partant du principe que “tout le monde a un smartphone”, certaines messageries comme Signal ou Telegram ont d’ailleurs fait le pari de prendre un numéro de téléphone comme base de l’identité, et non pas un email ou un autre compte. Ce qui facilite l’inscription, permet de retrouver tous ses contacts très facilement, et permet de sortir de Whatsapp, filiale de Facebook, très simplement en pratique.
ça permet aussi de faire du commerce d’une donnée identifiant une personne de façon assez forte partout dans le monde (le numéro IMEI, le VIN du téléphone, l’adresse MAC, l’identifiant publicitaire adwords ou facebook), et de compter sur un fournisseur d’identité à l’international déjà existant: les services télécom.
C’est votre numéro IMEI qui permet à votre opérateur Français de vous dire « coucou, vous venez de passer la frontière, voilà comment ça se passe le roaming et voici les tarifs » ou encore « bienvenu dans tel pays, on est trop sympa de vous facturer seulement 7€ la minute si vous appelez vers la France métropolitaine »
La mort des entreprises
Un logiciel privateur, (et donc fermé à la contribution et à l’audit du fonctionnement par des gens externes à l’entreprise) maintenu par une entreprise n’est pérenne que tant que ladite entreprise qui le maintient décide de faire bosser des gens compétents dessus… et que l’entreprise elle même reste en vie. Si un des deux disparaît, c’est fini. Pas forcément tout de suite, mais très rapidement. N’allez pas croire que c’est réservé aux petites entreprises et admirez donc le nombre de logiciels tués par Google sur son cimetière, qui propose également des alternatives.
Contrairement à un logiciel libre, qui peut parfaitement survivre à ses créateurs et être repris par d’autres, tant qu’il reste accessible à la communauté. C’est pourquoi tout mettre sur Github, détenu par Microsoft et uniquement là bas est forcément une bêtise. L’enjeu de la pérennité de la forge logicielle et du partage des sources sous une licence adaptée est donc toute aussi importante. C’est ce qui fait que github et NPM ont été rachetés par Microsoft, et Gitlab par Google.
La messagerie par dessus l’email
Deltachat fait ça, à la façon dont Silence le fait avec les SMS sans utiliser ses données mobiles, c’est un bon moyen de communiquer chiffré de bout en bout sans attendre que le protocole qu’on utilise implémente correctement un protocle de qualité.
Communiquer avec ceux qui n’ont pas de compte
L’enjeu d’une communication globale et privée est donc de taille, et ne saurait passer par un service centralisé sujet à la mort ou au bon vouloir des actionnaires d’une entreprise.
Suite à une conférence de uwu et owo à Pas Sage en seine 2019, j’ai lancé un sondage recensant quelles sont les messageries pour lesquelles vous avez un compte.
les modes changent vite dans le domaine, et mon sondage n’est déjà plus représentatif de ce qui se pratique.
Bref, on est pas sortis des ronces, peut être qu’un jour on fera comme en chine et tout le monde se mettra d’accord pour que toute notre vie et donc nos communications soit entièrement régie par un homme du milieu autoritaire pour ne pas avoir de choix et n’utiliser qu’une seule messagerie sur laquelle il a entièrement la main. Mais heureusement, ce jour n’est pas encore arrivé, et si on veut une messagerie libre on a le choix.
Personnellement j’utilise un mix de messageries en tentant avec plus ou moins de succès de faire des ponts entre chaque en montrant qu’ils existent et quels sont les avantages aux gens qui l’ignorent. Notamment en leur apprenant qu’il ne faut pas croire qu’utiliser un outil nous protège de tout et conviendra forcément à nos besoins, contrairement à ce que des campagnes de com et d’influence passent leur temps à nous rabâcher. Après il faut reconnaître que des outils comme Signal et Protonmail sont vachement bien foutus et qu’énormément de gens ont significativement amélioré leur sécurité et confidentialité de communication rien qu’en les adoptant, malgré leurs défauts.
Comme dirait un grand philosophe: « y’a tout le monde sur ta messagerie? ça veut dire les tueurs en série, et les pervers? je veux surtout pas y aller! »
On dirait du Elon Musk qui parle des transports en commun, mais non, c’est Vdubs qui fait la promotion des messageries libres 😀
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!
Pour avoir une rétrospective des évènements auquels j’ai pris des photos, rien de tel qu’un bon listing récursif de dossiers photos.
Il se trouve que pendant un moment j’ai séparé mes photos dans des dossiers correspondant aux dates des évènements, ce qui est loin d’être optimal en terme de navigation et d’information associées. Depuis que j’ai mis en place un système de tags sur les noms de fichiers je fais en sorte de sortir de ce principe d’informations localisées dans le chemin du fichier.
la commande tree permet de faire un listing récursif de tous ses dossiers, mais c’est plus marrant de voir comment faire ça en nodejs.
Voici donc un script pour faire ça sur 3 niveaux de profondeur à partir d’un chemin prédéfini, celui de la base de nos photos:
plus qu’à faire le lancement du script et sauvegarder la sortie de console dans un fichier texte pour voir ce que l’on a fait comme sous dossiers d’évènements.
node index.mjs > dossiers_liste.txt
on pourrait ensuite s’amuser à créer des tâches orgmode avec la date prise dans la hiérarchie de fichiers afin de les faire apparaître dans notre agenda, ou dans un rapport annuel utilisant nos fichiers orgmode, mais ça demande à ce que le cheminement des évènements ait été décrit de façon cohérente.
Havez fun!
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
C’est pas le tout d’avoir plein de photos rangées selon leur évènement dans une liste de dossiers décrivant ces évènements, si on veut que les informations de ces évènements soient dans le nom de fichier et que ça soit tagué correctement pour pouvoir les retrouver facilement, il faut de bons outils pour ça.
J’ai ceci:
/photos/2023/01 evènement bidule/0001.jpg
/photos/2023/01 evènement bidule/0002.jpg
/photos/2023/01 evènement bidule/0003.jpg
/photos/2023/02 festival truc/0001.jpg
/photos/2023/02 festival truc/0002.jpg
/photos/2023/02 festival truc/0003.jpg
Et je souhaite avoir cela:
/photos/2023/01 evènement bidule 0001.jpg
/photos/2023/01 evènement bidule 0002.jpg
/photos/2023/01 evènement bidule 0003.jpg
/photos/2023/02 festival truc 0001.jpg
/photos/2023/02 festival truc 0002.jpg
/photos/2023/02 festival truc 0003.jpg
Voici justement un petit script pour ça confectionné dans ma cuisine: Rename File Folder.
Pour l’appeler facilement, un petit alias bash et zou, rff fera le taf dans tout le dossier courant de votre terminal.
Dans votre fichier ~/.bash_aliases:
alias rff="python /home/Nextcloud/ressources/workflow_nextcloud/files_management/rename_photo_folder.py" # mettez votre script où vous voulez
Comme toujours, il vaut mieux tester les renommages de fichiers en masse sur de petites portions de copie de fichiers.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
La nouvelle est tombée ce Lundi 10 Avril 2023, le code source de Mastodon a fuité.
Grâce à mon expérience de SEO Manager expert en gestion géopolitique des tags je vous raconte ici ce qu’il faut retenir afin que vous gagniez un maximum d’argent en moins de 24h avec votre compte Mastodon. Tout d’abord je tiens à remercier mes sponsors, l’OSINT et les Anonymousse sans qui rien de tout cela n’aurait été possible, je vous en dirai un peu plus en fin d’article, alors restez thuné et n’oubliez pas de lâcher vos commz et des brouzoufs, tant vous allez devenir riche sur internet avec votre page Mastodon!
Ça n’a pas pu vous échapper tant les journaux n’arrêtent pas d’en parler, c’est juste dément:
Voilà ce que vous devez faire pour gagner un max de pognon sur Mastodon: avoir des gens qui vous donnent du pognon. Et pour ça il faut se fondre dans la culture du milieu propre à la multitude de sites web qui composent la plateforme. C’est carrément ouf!
L’algorithme de tri de votre flux d’actualité est basé sur des calculs qui font appel à des maths avancées au moins à 2 mètres devant la porte d’entrée, donc accrochez vous, je vais vous révéler tout ça.
Les posts qui sont le plus mis en avant dans le flux d’actualité de vos adeptes, des spambots, de vos abonnés, c’est précisément l’intégralité de vos posts. Oui, vous avez bien lu, TOUS vos messages parviennent à tous les abonnés qui ont fait la démarche de s’inscrire à votre compte de spam communication. C’EST UN CHOIX RADICAL DE DINGUE! L’engagement généré par des flux d’actualités curationnés par des humains qui se font des recommandations de bouche à oreille est décuplé comparé à d’autres lieux où le tri des flux d’actualités se fait au bénéfice seul des annonceurs prêts à tout pour vendre leur merde.
Mais ce n’est pas tout!
La modération des posts est faite principalement par des humains, donc si vous publiez de la mouise, vous serez masqués par les équipes de modos humaines, même si vous êtes pétés de thunes, c’est carrément dingue non?
Ainsi, les annonceurs les moins éthiques sont éconduits vers le caniveau, et c’est tant mieux.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
This is post 6 of 8 in the series “gestion de l'information personnelle”
Décrit la gestion des fichiers et des informations personnelles que j’utilise pour tirer du sens de mes archives et les conserver de façon pérenne et découvrable, uniquement avec des outils respectueux de la vie privée
Près d’un tiers de mes archives sont des doublons. Mais ça c’était avant.
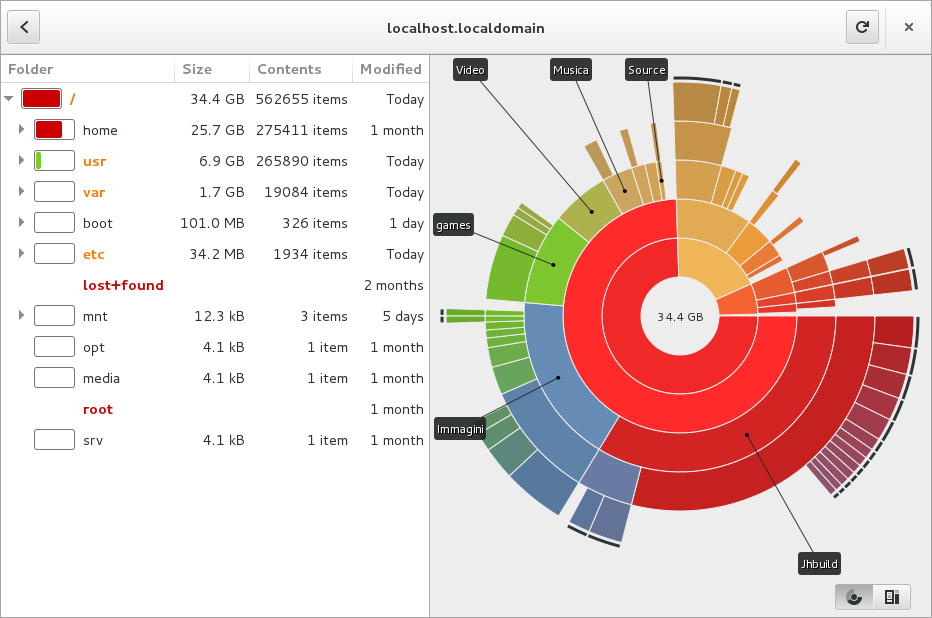
Pour savoir quel dossier prend plein de place, il existe des outils comme Ncdu en ligne de commande si vous n’avez pas d’environnement de bureau, ou Baobab, aka l’analyste d’utilisation de disque installé de base sur Debian / Ubuntu. cela vous permettra de cibler les dossiers les plus gros.
Spoiler: ce sont les vidéos et les photos qui prennent le max de place chez la plupart des gens.
Vous pouvez cibler un dossier en particulier et voir ce qui remplit votre disque. C’est une très bonne première approche. On a juste à naviguer dans le graphe, ou dans les noms de dossiers, pour voir sur quoi on doit concentrer nos efforts. On peut ouvrir les dossiers dans notre explorateur de fichier pour aller voir en détail, mais on peut aussi mettre à la poubelle des dossiers entiers depuis Baobab.
Il ne faudra pas oublier de vider votre corbeille ensuite pour vraiment bénéficier de l’espace libéré.
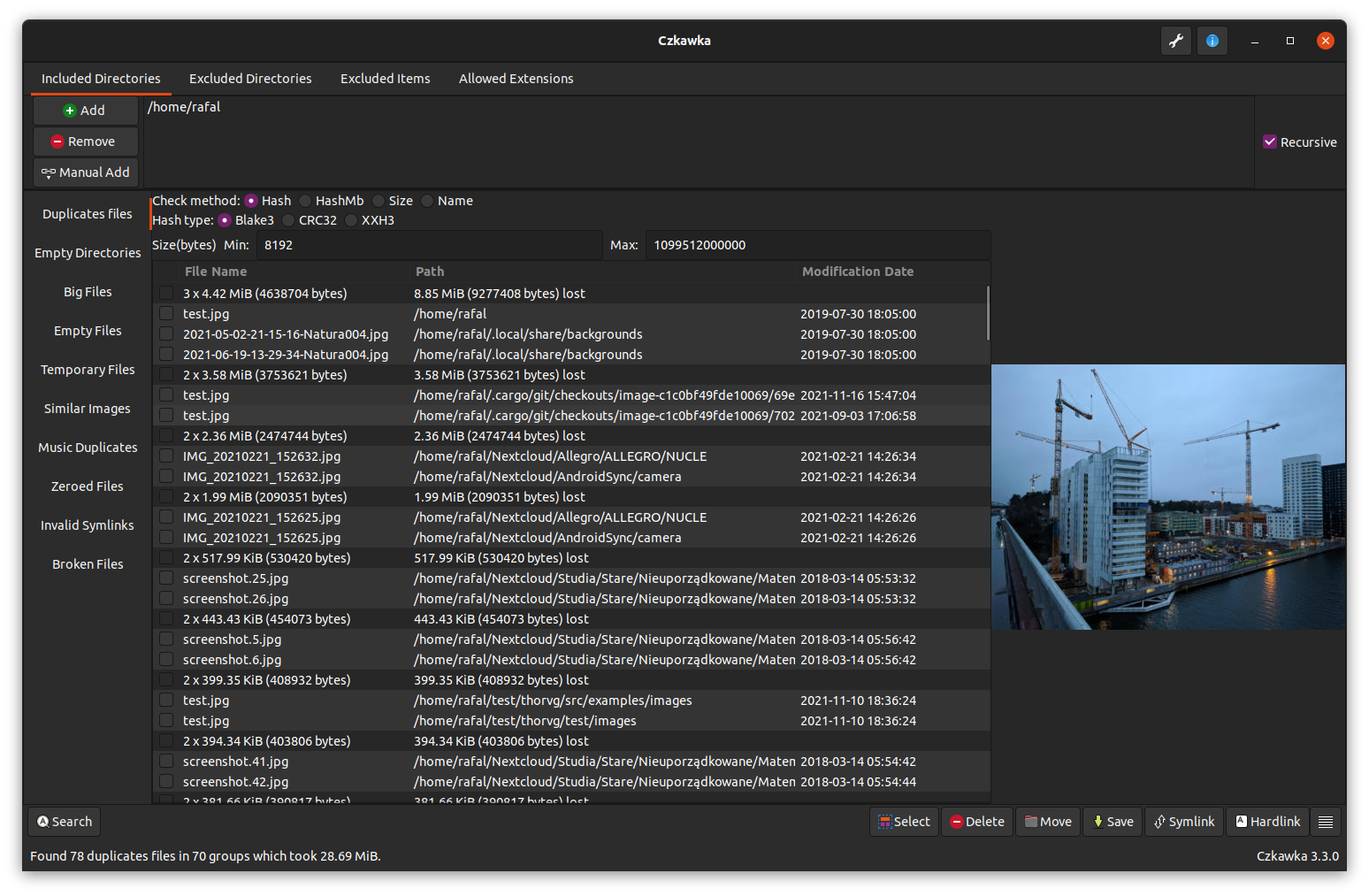
Repérer les doublons avec Czkawka
si vous aviez l’habitude de fslint qui n’est plus maintenu c’est pareil. Voici le site officiel pour l’installer: https://qarmin.github.io/czkawka
Vous pouvez utiliser snap pour ça, c’est le plus simple.
snap install czkawka
# et pour le lancer
snap run czkawka
Pour s’en servir on sélectionne un ou des dossiers où fouiller, via le bouton vert « add ». Puis on clique sur « search » en bas à gauche. Et au bout de quelques secondes ou minutes si vous comparez beaucoup de trucs, vous avez les résultats. Vous pouvez ensuite cocher les fichiers à dégager, et appuyer sur la touche « suppr » de votre clavier pour les mettre à la poubelle. Ou faire d’autres actions comme proposé en bas à droite. Vous pouvez désactiver l’aperçu des images au clic sur le nom de fichier dans les paramètres, bouton « outil clé » en haut à droite.
Pour accélérer les comparaisons de hashs de fichier je vous recommande d’activer cette option dans les paramètres pour ne comparer qu’une portion des fichiers au lieu de leur intégralité.
L’intérêt de cette comparaison par hash c’est que ça permet d’éliminer des doubles qui ne se nomment pas pareil.
Vous pouvez aussi exclure certains motifs de dossiers pour accélérer les recherches. ça se passe dans les onglets en haut de l’écran, section « répertoires exclus ». Dans l’onglet configuration des éléments j’ai exclus certains dossiers:
On a donc en résultat une liste des fichiers en double, triés du plus lourd au moins lourd. Vous pouvez vous amuser à les supprimer un par un 😀 ou essayer de faire des choses plus malines.
Un double clic droit sur une ligne de fichier vous permettra d’ouvrir le dossier contenant le fichier dans votre explorateur de fichier. C’est très pratique pour repérer les contenus qui ont été copiés dans plusieurs dossier, afin de couper coller le contenu de l’un dans l’autre et de fait supprimer une énorme masse de doublons.
Czkawka permet aussi de faire de la recherche d’image similaire. Je ne l’ai pas utilisé mais ça semble prometteur.
Les quelques similarités que je cherche à supprimer sont des redimensions de fichiers réduites pour publication en ligne. un filtre sur des termes comme « thumb » ou « small » suffisent à en retrouver un paquet.
Restez groupir les photos et vidéos.
Exemple avec mes photos, elles sont dans un dossier nommé stockage-syncable/photos qui contient plusieurs trucs. Notamment des dossiers d’années, qui contenaient des dossiers mensuels, avec des dossiers groupant des jours et des évènements sur plusieurs jours. Un bon moyen de dédoubler tout ça c’est de faire du renommage de masse basé sur les métadata des photos/vidéos, et de tout réunir dans un seul dossier. Reste ensuite à tout répartir par année à coup de script. Et à mettre dans un coin dédié les fichiers qui demandent un traitement ou des incertitudes de doublonnage à lever.
J’avais des doublons pour faire des sélections d’albums, certains à imprimer, certains pour désigner des étapes de chantier de maison ou des lieux de capture pour des séquences de mappage openstreetmap à 360°.
Une fois que les choses sont élaguées des parties les plus évidentes on peut se demander comment faire en sorte de mettre tout ça en qualité, et surtout, à quoi ça ressemble des archives qui seraient de très bonne qualité.
La suite au prochain épisode!
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
This is post 5 of 8 in the series “gestion de l'information personnelle”
Décrit la gestion des fichiers et des informations personnelles que j’utilise pour tirer du sens de mes archives et les conserver de façon pérenne et découvrable, uniquement avec des outils respectueux de la vie privée
Imaginez y’a des gens qui s’amusent régulièrement à tenter d’exporter leurs photos, vidéos et documents récupérés depuis leur téléphone pour tenter de s’en servir sur un ordi, ou un autre, et à avoir du mal à retrouver leurs documents quand ils en ont besoin. Qui pestent contre le protocole MTP qui n’est pas capable d’utiliser pleinement la rapidité d’un cable USB. Qui finissent pas utiliser Wifi File Transfer pour copier leurs fichiers du téléphone vers leur ordi, ou qui trouvent ça trop galère et du coup se disent que refiler tout à un bon gros GAFAM est une solution pérenne, haha ! Alors que les GAFAMS n’ont de cesse de tuer les uns après les autres leurs services de surveillance.
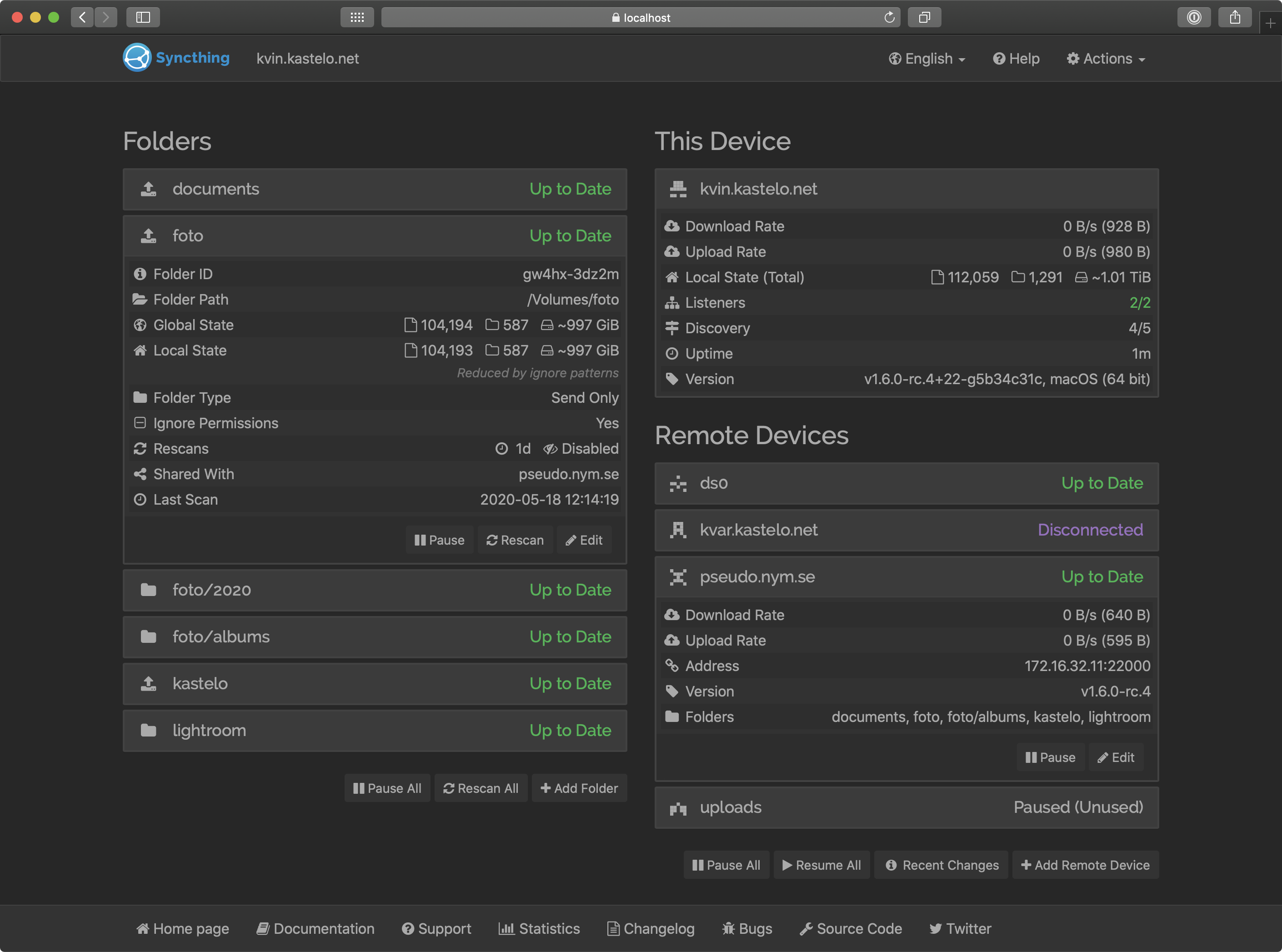
Alors qu’il suffit d’avoir sa propre gestion de fichiers syncronisés chez soi en pair à pair, par exemple avec Syncthing, ou un nextcloud chez des CHATONS.
Pour Nextcloud
Il vous faudra:
un compte nextcloud sur un serveur
l’appli client nextcloud sur votre téléphone, connecté à votre compte serveur
avoir l’upload automatique activé depuis votre téléphone, et ce même si vous n’avez pas le wifi connecté (voir dans les paramètres d’upload automatique de l’appli mobile)
avoir le client nextcloud installé sur un ordinateur, connecté à votre compte serveur
Pour Syncthing
Il vous faudra:
faire marcher syncthing sur votre ordi
faire marcher syncthing sur votre ordiphone
configurer les dossiers à faire syncroniser
appairer les deux identifiants de syncronisation
accepter la syncronisation sur les deux appareils, choisir les dossiers concernés
et tadam, vos photos, vidéos et documents seront téléchargés sur votre ordi. Vérifiez dans les paramètres que l’envoi vers le serveur nextcloud se fait même si vous n’êtes pas connecté au wifi.
Une fois l’upload fait automatiquement vous aurez vos médias téléchargés dans votre dossier Nextcloud sur votre ordi, par défaut dans votre dossier de /home/mon_utilisateur/Nextcloud/InstantUpload. Ce dossier de destination est bien sûr modifiable, tout comme votre client Nextcloud vous permet de syncroniser plusieurs dossiers différents, de ne pas forcément tout syncroniser de ce qui se trouve sur votre serveur Nextcloud, et pas forcément dans le dossier /home/mon_utilisateur/Nextcloud. Mais bon, pour garder l’exemple simple on va prendre les paramètres par défaut.
J’ai un dossier pour mes photos et vidéos à ranger, il me suffit de déplacer automatiquement les médias récupérés depuis le dossier InstantUpload vers celui ci, de les renommer automatiquement pour suivre ma convention de nommage avec des tags, et de les déplacer dans le dossier annuel. ça se fait très simplement avec un seul fichier de script bash, qui est exécuté toutes les 5 minutes sur mon ordinateur d’archivage.
Comme le dossier InstantUpload distingue dans des sous dossiers les médias que j’ai capturé par mon téléphone et ceux que j’ai téléchargé, je peux les ranger automatiquement avec un simple couper-coller fait par la commande mv (move). Je pourrai mettre des descriptions et des tags ultérieurement avec mon gestionnaire de photos scriptable Geequie, avec mes raccourcis clavier configurés via ma procédure d’installation de gestion de fichiers.
Le meilleur moyen d’éviter que le bazar soit partout, c’est de le concentrer dans un seul dossier. Donc pour tous les autres trucs que je récupère sur mon téléphone, je peux les envoyer dans mon dossier de bazar.
Ne reste plus qu’a se consacrer un peu de temps à autre, via un rappel d’agenda par exemple ou une revue hebdomadaire (coucou la méthode GTD) à faire disparaître le bazar, soit en truc rangé, soit dans le néant comme le conseille Marie Kondo.
le fichier de crontab:
#Ansible: run nextcloud workflows of tykayn
*/5 * * * * /bin/bash ~/Nextcloud/ressources/workflow_nextcloud/cronjob_nextcloud.sh
# back pictures to ARCHIVE_SYNCABLE
logDate 'copy of Nextcloud InstantUpload photos'
mv ~/Nextcloud/InstantUpload/Camera/* "$PHOTOS_TO_DISPATCH" | tee -a $LOG_FILE_BACKUP 2>&1
mv ~/Nextcloud/inbox/instantUpload/* "$PHOTOS_TO_DISPATCH" | tee -a $LOG_FILE_BACKUP 2>&1
#mv ~/Nextcloud/inbox/instantUpload "$PHOTOS_TO_DISPATCH" | tee -a $LOG_FILE_BACKUP 2>&1
guessfilename "$PHOTOS_TO_DISPATCH/$CURRENT_YEAR*"
cd $PHOTOS_TO_DISPATCH
move2archive --archivepath=$PHOTOS_FOLDER "$CURRENT_YEAR*"
echo ' ' >> $LOG_FILE_BACKUP_DATES
echo "### ${today} medias in $ARCHIVE_SYNCABLE/photos/$CURRENT_YEAR" >> $LOG_FILE_BACKUP_DATES
ls -l "$ARCHIVE_SYNCABLE/photos/$CURRENT_YEAR" | wc -l | tee -a $LOG_FILE_BACKUP 2>&1
Secouez le tout avec une mise en archive chiffrée par borg backup, syncronisez avec des supports distants, et voilà qui est automatiquement rangé.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies.
Le plus simple nous pour nous faire connaître étant de partager cet article.
Quelques nouveautés avec borg version 2, les commandes changent un peu, il est plus rapide, plus dur, meilleur, plus fort. Fait amusant, je l’ai utilisé sans savoir que c’était une référence à une série pas très connue que seuls des gens vachement plus vieux que moi regardaient.
On va commencer par définir un fichier contenant un mot de passe que Borg va pouvoir utiliser pour chiffrer les fichiers du dépot.
On définit quelques variables en Bash dans un fichier afin de ne pas avoir à se répéter partout. Faites chauffer votre terminal préféré:
# --------- archives dans un pool zfs nommé poule sur mon ordinateur nommé spaceship. # --------- Ce nommage est arbitraire, vous pouvez bien sûr mettre ce que vous voulez et sauvegarder plusieurs dossiers tout aussi arbitraires. # --------- Pour cet exemple on va dire que ce qu'on veut sauvegarder n'est pas l'intégralité de notre home mais un autre dossier auquel on fera référénce via une variable en bash par la suite.
export ARCHIVE_SYNCABLE="/home/poule/encrypted/stockage-syncable" # place where we have our things sorted, other than home export BORG_PASS_FILE="$ARCHIVE_SYNCABLE/.ma-borg-passphrase" mkdir -p $ARCHIVE_SYNCABLE
editor BORG_PASS_FILE # on définit notre phrase de passe dans notre éditeur de texte favori export BORG_PASSCOMMAND="cat $BORG_PASS_FILE" # get the borg repo pass
for item in "${EXCLUDE[@]}"; do exclude_opts+=( --exclude="$item" ) done
export exclude_opts
# --------- création du dossier qui va contenir notre dépot borg mkdir -p $SPACESHIP_NEW_BORG_REPO
# --------- Installation de borg version 2 avec pip pip install "borgbackup==2.0.0b5" borg --version
# --------- vous devriez voir marqué "borg 2.0.0b5", si vous ne le voyez pas, relancez votre terminal
Et voilà on peut maintenant créer une nouvelle sauvegarde avec un dossier contenant peu de choses dans un premier temps.
Créer un nouveau dépôt
Ici on demande la création d’un dépot chiffré par plusieurs algorithmes contenant sa clé, qui nécessite une phrase de passe, que nous avons défini dans un fichier texte ci dessus. La variable BORG_PASSCOMMAND sera utilisée par borg pour aller chercher cette phrase.
borg rcreate --encryption=repokey-blake2-aes-ocb -r $BORG_REPO
# et voilà un "repository" créé, on va pouvoir le remplir de plusieurs sauvegardes
Créer une archive dans le dépôt
pour l’exemple j’ai précisé que je souhaitais une compression zstd de niveau 9, soit le niveau maximum.
borg create $BORG_REPO::encrypted_spaceship_{now} $ARCHIVE_SYNCABLE "${exclude_opts[@]}" --progress --verbose --stats --compression zstd,9
Pour notre exemple, la partie $ARCHIVE_SYNCABLE désigne un dossier que l’on veut inclure dans notre sauvegarde, mais on peut mentionner plusieurs chemins vers des dossiers ou des fichiers séparés d’un espace si on le veut.
Enlever les anciennes sauvegardes de notre dépot en faisant un tri automatique.
Pour convertir votre archive borg existante, y’a une commande mais ça ne marche pas 😀
Automatiser dans un cronjob
Plus qu’a faire vos commandes dans un fichier exécutable, par exemple localisé dans un dossier nextcloud situé ici: ~/Nextcloud/ressources/workflow_nextcloud/sync_spaceship.sh et à le lancer périodiquement dans un cronjob. Pour modifier votre table de commandes cron:
crontab -e
Et rajouter ceci dans votre crontab pour lancer ce script toutes les 20 minutes par exemple:
# lancer le script de sauvegarde toutes les */20 * * * * /bin/bash ~/Nextcloud/ressources/workflow_nextcloud/sync_spaceship.sh
Le site web crontab.guru pourra vous aider à clarifier la périodicité de vos sauvegardes. Pour déterminer une périodicité optimale, il faut voir le temps que prend votre sauvegarde à se faire.
Si vous aimez ce que nous faisons à Cipher Bliss, vous pouvez nous soutenir de plusieurs façons: en faisant un micro don sur liberapay , ou en cryptomonnaies. Le plus simple nous pour nous faire connaître étant de partager cet article. Suivez moi sur Mastodon @tykayn@mastodon.cipherbliss.com. Ce site restera libre comme un gnou dans la nature et sans pubs, parce qu'on vous aime. Que la source soit avec vous!

 Le plus simple nous pour nous faire connaître étant de partager cet article.
Le plus simple nous pour nous faire connaître étant de partager cet article.